問題設定:PDFファイルの文書自動要約器
PDFファイルの文書自動要約は、ペーパーレス化やDXのようなキーワードが謳われる時代の中でも、まだ高いニーズを誇っている。確かに、PDFファイルをメールに添付して送り付ければ、「ハンコ」を求めない限りは、ペーパーレスなやり取りが実現するだろう。また、PDFという装置は列記とした「IT技術」だ。だから、「IT技術を導入すればDXが実現する」と考えるレガシーな機関も、継続的にPDFファイルを使い続けるだろう。
こうした背景を簡単に概観するだけでも、PDFファイルを読む仕事が無くなるという期待は薄いと考えられる。決算短信、目論見書、学術論文などのような文書は、未だにPDFファイルで配布される。しばしばその内容は、少なくても3行以上は記述されている「長文」となっている。
ペーパーレスとDXを成し遂げた輝かしい時代が到来したとしても、PDFファイルの文書自動要約に対するニーズは尽きないと考えられる。
派生問題:PDFファイル
多くの場合、PDFファイルからテキストデータを抽出するには、専用のライブラリが必要になる。pdfminer2は、このライブラリの代表例として知られている。
2020年の時点で、pdfminer2の保守は休眠している。現在このライブラリのメンテナンスはpdfminer.sixによって引き継がれている。しかしこのライブラリの参照問題を把握するには、pdfminer2の設計思想にまで遡る必要がある。
pdfminer2の公式ドキュメントでは、データマイニングの観点から、PDFファイルという存在そのものが悪者として言及されている。
「PDFは悪だ。これは「文書」と呼ばれていながら、マイクロソフトのWordやHTMLのドキュメントとは全然違う。PDFは、むしろ図解(graphic representation)の一種であろう。(略)大抵の場合、PDFには文や段落のような論理的な構造は無い。そしてPDFは紙のサイズが変わった時に自動的に適用させることができない。(略)知っていたことだが、醜い。もう一度言いたい。PDFは悪だ。」
https://euske.github.io/pdfminer/programming.htmlより。(参照日時:2020/07/13 20:00)
問題解決策:pdfminer2
確かに、PDFは論理的なデータ構造を有していない。一般に文書というのは非構造化データで、日本語の場合であれば形態素解析やN-gramのような機能で前処理を施さなければ、とても分析可能な状態にはなり得ない。
PDFファイルで学術論文のような文書を扱う場合は、これに加えて、更に非論理的な構造として配置されているPDFデータをパーサに掛けてから文書として再構造化していかなければならない。オブジェクト指向設計的に、この責任を全うするには途方も無い処理が必要となるようだ。だから、公式ドキュメントで掲載されている概念的なクラス図では、単純にパーサに掛ける処理だけでも、PDFParserとPDFDocumentという相互に参照し合う二つのオブジェクトが要求されている。
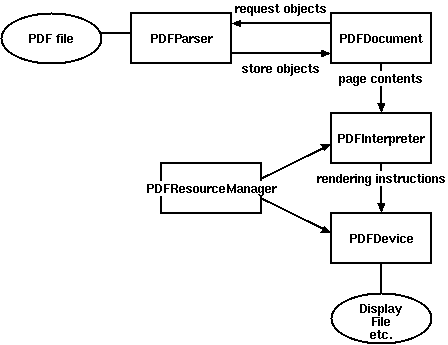
実装水準のユースケースとして掲載されているコードサンプルを観てみよう。確かに、基礎的な使い方(Basic Usage)でありながら、インポートすべきライブラリが多数あるようだ。
[cc lang=”python”]from pdfminer.pdfparser import PDFParserfrom pdfminer.pdfdocument import PDFDocument
from pdfminer.pdfpage import PDFPage
from pdfminer.pdfpage import PDFTextExtractionNotAllowed
from pdfminer.pdfinterp import PDFResourceManager
from pdfminer.pdfinterp import PDFPageInterpreter
from pdfminer.pdfdevice import PDFDevice
# Open a PDF file.
fp = open(‘mypdf.pdf’, ‘rb’)
# Create a PDF parser object associated with the file object.
parser = PDFParser(fp)
# Create a PDF document object that stores the document structure.
# Supply the password for initialization.
document = PDFDocument(parser, password)
# Check if the document allows text extraction. If not, abort.
if not document.is_extractable:
raise PDFTextExtractionNotAllowed
# Create a PDF resource manager object that stores shared resources.
rsrcmgr = PDFResourceManager()
# Create a PDF device object.
device = PDFDevice(rsrcmgr)
# Create a PDF interpreter object.
interpreter = PDFPageInterpreter(rsrcmgr, device)
# Process each page contained in the document.
for page in PDFPage.create_pages(document):
interpreter.process_page(page)
[/cc]
問題解決策:pdfminer.six
後にpdfminer.sixのAPI文書で解説されたように、PDFMinerは、文字の配置に関するヒューリスティックなアルゴリズムに準拠することで、PDFファイルの構造の一部を再構成している。それは、近傍の文字同士を意味のあるグループとして分類することで、文や段落を探索するアルゴリズムである。
大多数のPDFファイルは、確かに適切に構造化されたテクストを配置しているように視える。しかし実際、PDFファイルには、段落や文に相当する情報が無い。テクストについて言えば、PDFファイルは文字とその配置のみを認識している。例えばPDFファイルは、段落を構成する文字と図表やヘッダー/フッターを構成する文字とを区別しない。全てのテクスト情報は、文字と位置関係に還元されてしまう。まるで一文字一文字が、窓を持たないモナドの如く、単一で自己完結しているバイトシーケンスとなっている。
それ故にPDFMinerは、文字の位置関係を探索する「レイアウト分析アルゴリズム(Layout analysis algorithm)」を採用せざるを得なかった。このアルゴリズムは、三つの異なる段階で構成される。まず文字を単語と行に分類し、次に行をボックスに分類し、そして最後にテクストのボックスを階層的に分類する。これによりこのアルゴリズムは、PDFファイルの各ページにおけるレイアウトオブジェクトに対し、その順序付けられた階層を把握する。
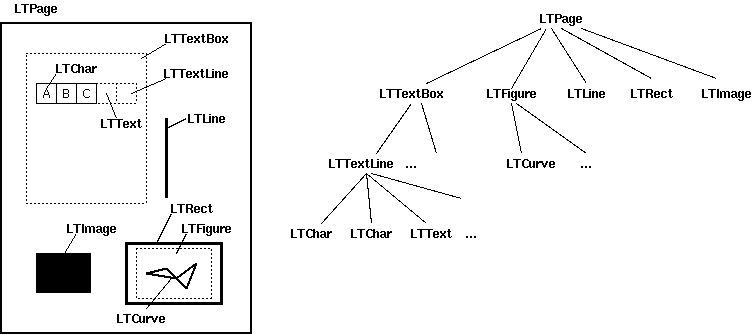
問題設定:PDFファイルの文書自動要約
観てきたように、PDFファイルからテキストを抽出するだけでも、多くの事柄を考えなければならなかった。しかし一旦テキストを抽出してしまえば、後は既存のテキストマイニングや自然言語処理のモデルを機能的に再利用するだけで、文書自動要約は実現可能になる。
問題解決策:pysummarization
ここでは、pysummarizationのライブラリを用いたPDFファイルの文書自動要約を試行してみよう。
まずは対象となるPDFファイルのURLを指定する。
[cc lang=”python”]url = “path/to/your/file.pdf”[/cc]
何度もアクセスする場合は、ローカルのWebサーバ等に配置してアクセスした方が良いだろう。
次に、pysummarizationのモジュールをインポートする。
[cc lang=”python”]from pysummarization.nlpbase.auto_abstractor import AutoAbstractorfrom pysummarization.tokenizabledoc.mecab_tokenizer import MeCabTokenizer
from pysummarization.web_scraping import WebScraping
from pysummarization.abstractabledoc.std_abstractor import StdAbstractor
from pysummarization.abstractabledoc.top_n_rank_abstractor import TopNRankAbstractor
from pysummarization.readablewebpdf.web_pdf_reading import WebPDFReading
[/cc]
そして、必要なクラスを初期化し、変数:urlを入力する。
[cc lang=”python”]# The object of Web-scraping.web_scrape = WebScraping()
# Set the object of reading PDF files.
web_scrape.readable_web_pdf = WebPDFReading()
# Execute Web-scraping.
document = web_scrape.scrape(url)
# The object of automatic sumamrization.
auto_abstractor = AutoAbstractor()
# Set tokenizer. This is japanese tokenizer with MeCab.
auto_abstractor.tokenizable_doc = MeCabTokenizer()
# Object of abstracting and filtering document.
abstractable_doc = TopNRankAbstractor()
# Execute summarization.
result_dict = auto_abstractor.summarize(document, abstractable_doc)
# Output summarized sentence.
[print(sentence) for sentence in result_dict[“summarize_result”]][/cc]
自動要約のデモ:決算短信
ここでは、2020年5月13日に公開された2020年度決算短信・説明会資料|楽天株式会社の『2020年度 第1四半期決算短信』というタイトルのPDFファイルを対象に、自動要約を試みよう。
― 2 ―決算短信(宝印刷) 2020年05月11日 20時10分 4ページ(Tess 1.50(64) 20181220_01)楽天株式会社(4755) 2020年12月期 第1四半期決算短信(Non-GAAPベース)前年同期(前第1四半期 連結累計期 間)当期(当第1四半期 連結累計期間)(単位:百万円)増減額増減率売上収益Non-GAAP営業利益又は損失(△)280,294117,977331,44351,149△18,136△136,11318.2%-%② Non-GAAP営業利益からIFRS営業利益 への調整酬費用は3,284百万円となりました。
当第1四半期連結累計期間において、Non-GAAP営業利益で控除される無形資産の償却費は2,634百万円、株式報前年同期(前第1四半期 連結累計期間)当期(当第1四半期 連結累計期間)(単位:百万円)増減額117,977△2,356△1,959113,662△18,136△136,113△2,634△3,284△278△1,325△24,054△137,716Non-GAAP営業利益又は損失(△)無形資産償却費株式報酬費用IFRS営業利益又は損失(△)③ 当第1四半期連結累計期間の経営成績(IFRSベース)当第1四半期連結累計期間における売上収益は331,443百万円(前年同期比18.2%増)、IFRS営業損失は24,054百万円(前年同期は113,662百万円の営業利益)、四半期損失( 親会社の所有者帰属)は35,319百万円(前年同期は104,981百万円の利益)となりました。
この変更に伴い、遡及適用前と比較して前第1四半期連結累計期間のインターネットサービスセグメントにおけるセグメント売上収益が879百万円減少、セグメント損益が774百万円減少、フィンテックセグメン トにおけるセグメント売上収益が276百万円減少、セグメント損益が2,821百万円減少、モバイルセグメントにおけるセグメント損益が259百万円減少しています。
なお、連結上の売上収益、Non-GAAP営業利益及び営業利益に与える影響はありません。
インターネッ― 3 ―決算短信(宝印刷) 2020年05月11日 20時10分 5ページ(Tess 1.50(64) 20181220_01)楽天株式会社(4755) 2020年12月期 第1四半期決算短信ト・ショッピングモール『楽天市場』や医療品・日用品等の通信販売等を行う『Rakuten 24』などにおいては、いわゆる「巣ごもり消費」の拡大に伴うオンラインショッピング需要の高まりにより、取扱高に押し上げの効果が見られました。
一方で、インターネット旅行予約サービスの『楽天トラベル』においては、新型コロナウイルス感染症拡大に伴う、外出自粛等の影響を強く受け、特に2020年3月以降の予約低迷、キャンセルが相次ぎました。
当第1四半期連結累計期間における各キャッシュ・フローの状況及び主な変動要因は次のとおりです。
この変更に伴い、遡及適用前と比較して前第1四半期連結累計期間のインターネットサービスセグメントにおける売上収益が879百万円減少、セグメント損益が774百万円減少、フィンテックセグメントにおける 売上収益が276百万円減少、セグメント損益が2,821百万円減少、モバイルセグメントにおけるセグメント損益が259百万円減少しています。
なお、連結上の売上収益、Non-GAAP営業利益、営業利益に与える影響はありません。
110,4331,112111,545377236-776301,320-1,0241,0244121152,5116821,6865,406― 16 ―決算短信(宝印刷) 2020年05月11日 20時10分 18ページ(Tess 1.50(64) 20181220_01)
新型コロナウイルスによる影響範囲や、売上収益の減少に伴う影響範囲が、セグメントごとに解説されていることがわかる。