問題設定:「安倍首相の健康不安」に関するTwitter上の反応について
2020年8月下旬、安倍首相の通院が報道され辞任の意向が示されるまでの間、Twitterでは、「安倍首相の健康不安」に関する多くの議論が展開されていた。一国のリーダーの健康状態は、国家の構造を揺るがす危機的状況を招き得る。緊張感が走るのも無理は無い。しかし一方で、こうした危機的状況は、旧くから踏襲されるべきと主張されてきた「伝統」や来るべき新しい時代の「将来像」、あるいは、こう言い換えて良ければ、「理念(Idee)」のようなものが叙述される時期でもある。
だがこうした新しい時代に関する理念の多くは、しばしば語り継がれることなく埋もれてしまう。そうした理念は、現時点の感覚から観れば、再現性が低く、新奇性が高く、それ故に省みられることの少ない「極端なもの」として見做されてしまう。
「リツイート数」や「いいね数」の多いインフルエンサーや著名人たちのツイートを観察するだけでは、こうした理念を網羅的に探索することはできない。インフルエンサーや著名人たちのツイートは、単に注目を集めているだけであって、必ずしも人々が重んじていた「伝統」や思い描いていた「将来像」を「代表」として纏め上げている訳ではないためである。
問題解決策:「安倍首相の健康不安」に関するTwitterの感情分析
この記事では、安倍首相の通院が報道された時期となる2020年8月17日から2020年8月24日までの間に叙述されていた理念の推論が如何にして可能になるのかを検討していきたい。
勿論、逐次ツイートを検索して、目視で隅々まで探せば、定性的に尤もらしい分析結果が得られるだろう。だがそれは負担が大きい。以下の線グラフは、「安倍首相 健康」のキーワード検索でヒットしたTwitterのツイート数を時間単位で集計した結果となる。
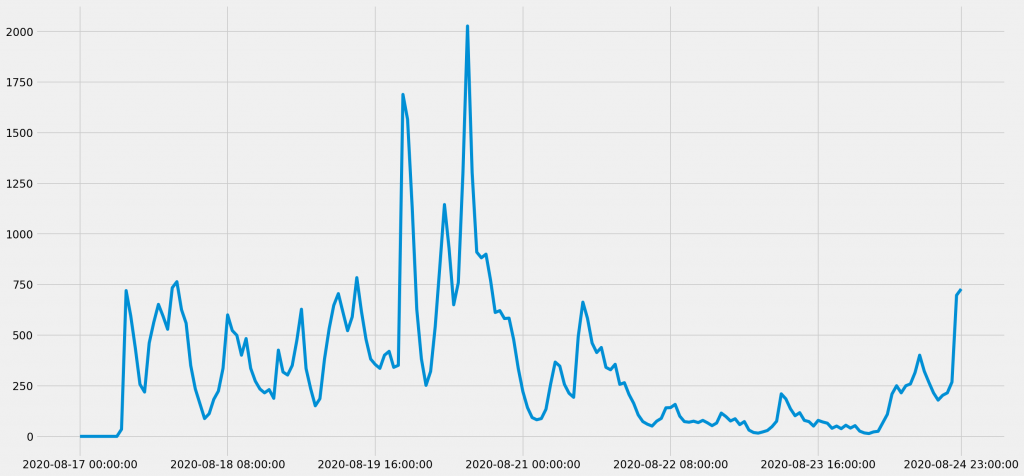
リツイートや引用ツイートなどの影響も加味すれば、分析対象の規模はより大きくなってしまう。また、「安倍総理 健康」や「安倍首相 通院」などの関連キーワードの検索結果も含めていけば、分析対象は膨大となる。これらを人間の眼で分析していくのは困難極まりない。
そこで、機械による単純化が有用となる。例えば、Twitterを対象とした「感情分析(Sentiment Analysis)」については、既に多くの研究者たち(Kouloumpis, E., et al., 2011, Severyn, A., & Moschitti, A., 2015, Jianqiang, Z., et al., 2018)によって、テキストマイニングや自然言語処理、あるいはニューラルネットワーク言語モデルを利用したアルゴリズムが提案されている。
多くのモデルは、「感情(Sentiment)」という概念を「肯定的(positive)」と「中立的(neutral)」と「否定的(negative)」に区別することで分析している。これは、言語学における「極性項目(Polarity item)」を定量化することで、ツイートに含まれている各ワードをこの極性に適合(fit)させていくという発想に基づいている。
問題解決策:「安倍首相の健康不安」に関するTwitterのトピック分析
一方で、単に主題(トピック)を抽出するという発想も可能だ。「安倍首相の健康不安」を巡るTwitter上の反応は、多くの意見の対立を派生させている。「争うこと」ができるのは「同じこと」についてのみなので、意見を共有できずに対立させている者たちは、主題を共有しているはずだ。だから、まずは主題を抽出するだけでも、各自の理念の探索を簡明にすることができる。
恐らく最も単純なトピック抽出は、出現頻度の高い「名詞」の単語を集計していくことだろう。次点で、「名詞」と「名詞」、「名詞」と「形容詞」、「名詞」と「形容詞」と「動詞」などの組み合わせで、共起表現やN-gramを集計する方法だ。
いわゆる「カルチュロミクス(Culturomics)」の理論は、今も尚時宜を得ている。カルチュロミクスとは、ゲノム解析を意味するゲノミクス(genomics)に倣った造語で、膨大な文献資料を材料に語彙などの変化を定量的に分析して、文化の潮流や人類の営みを分析する学問を意味する(Aiden, E., & Michel, J. B., 2013)。
共起頻度の時系列データ:「健康」と「不安」
実は、Twitterほどのビッグデータを前提とした場合、カルチュロミクスのような単純な集計方法であっても、全体像を把握するには十分な場合がある。例えば以下の線グラフは、「安倍首相 健康」のキーワード検索でヒットしたTwitterのツイートの中で、「健康」と「不安」という二つの名詞が140文字のツイート文内で共起している割合(リツイートやいいね、引用ツイートは加味していない)を集計したものだ。
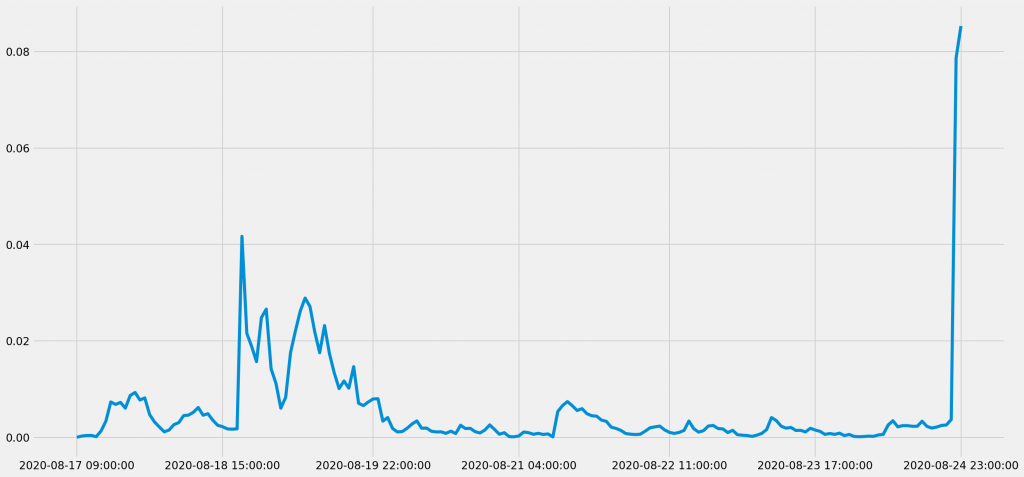
安倍首相の健康不安は、通院の報道後に一時的に話題になり、検査結果に関する情報が広まる8月24日に最高潮に達していたことがわかる。
共起頻度の時系列データ:「安倍首相」と「147日」
この間、安倍首相に関しては、健康不安に関して様々な主題が派生している。例えば同様の方法で集計して観ると、「安倍首相 健康」のキーワード検索でヒットしたTwitterのツイートにおいて、「安倍首相」と「147日」という単語の共起は、最初の通院の報道後に頻出していることがわかる。
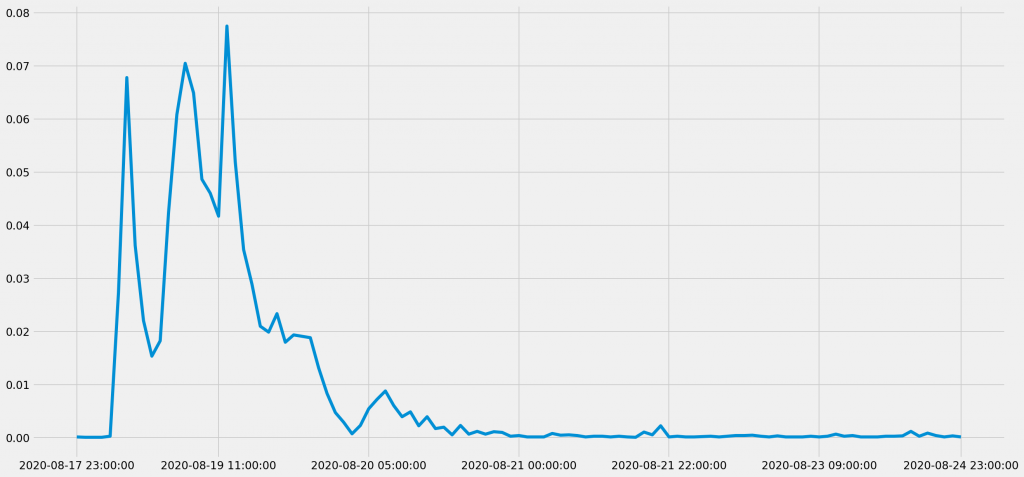
これは、この初期の時期に、安倍首相が147日間休まずに働いていたことについての議論が活性化していたことを示している。
共起頻度の時系列データ:「在職」と「記録」
一方、週の中盤には、「安倍首相 健康」のキーワード検索でヒットしたTwitterのツイートにおいて、安倍首相の「在職」の「記録」が主題になっていた。この記録を肯定的に評価する者たちと否定的に評価する者たちの議論が活性化していたのだと考えられる。
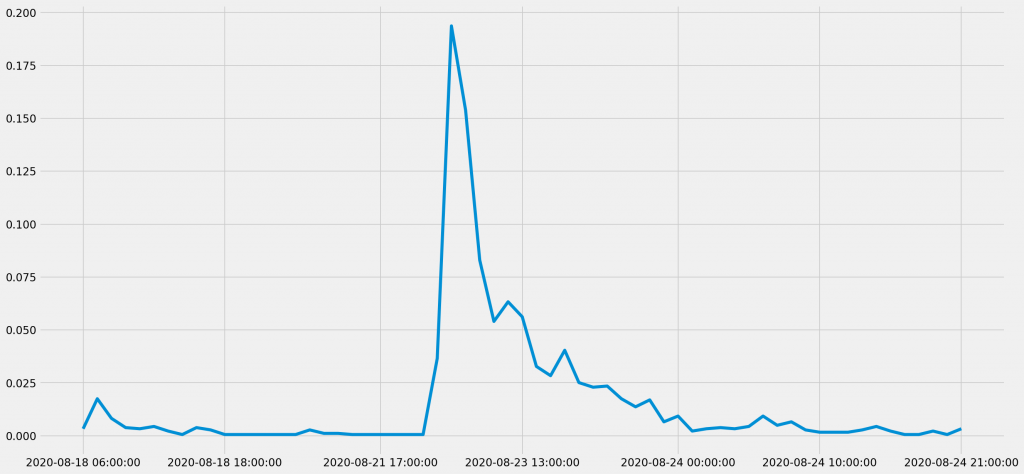
共起頻度の時系列データ:「検査」と「健康」
更に週の終盤には、「安倍首相 健康」のキーワード検索でヒットしたTwitterのツイートにおいて、安倍首相の「検査」と「健康」の共起が、上述した「健康」と「不安」の時系列データとは微妙に異なる分布で頻出していた。
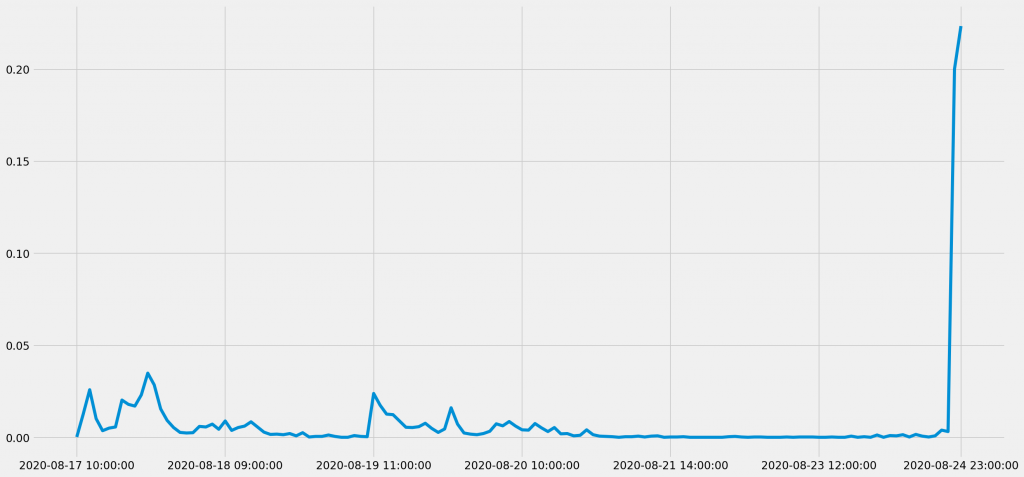
「健康」と「不安」の共起に比べれば、「検査」と「健康」の共起については、週の序盤・中盤にスパイクが発生していない。これは、当初安倍首相の健康不安が「147日間休まずに働いていたこと」に結び付けて論じられており、必ずしも「医療」の問題としては強調されていなかったのだと推論できる。また「在職」の「記録」が主題となったことで、相対的に共起頻度が下がったのだとも解せる。
日ごとの共起頻度TOP10
「安倍首相 健康」のキーワード検索でヒットしたTwitterのツイートに対して、日ごとに共起頻度の割合を集計し直し、それぞれの日で最も頻出した共起の組み合わせを並べて観ると、次のようになる。
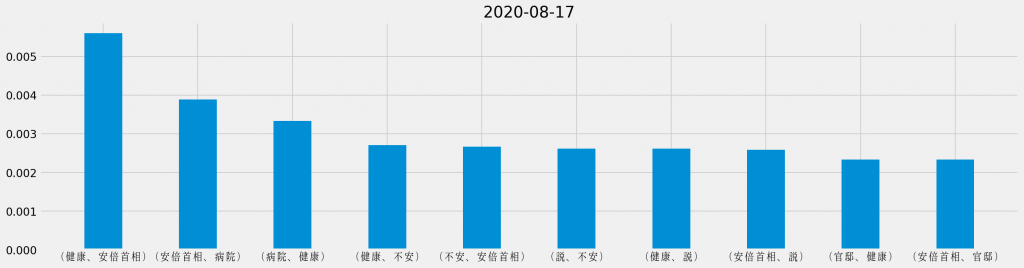
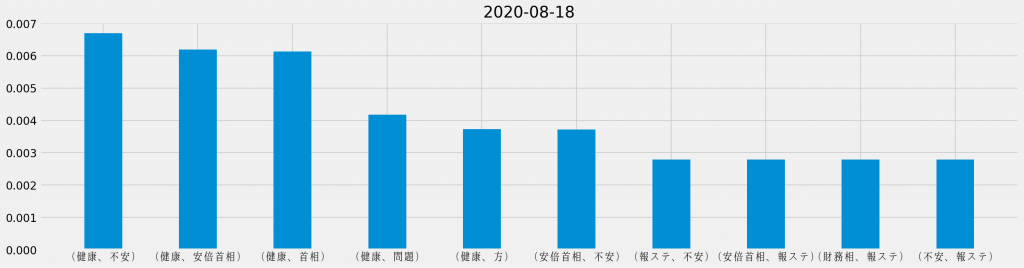
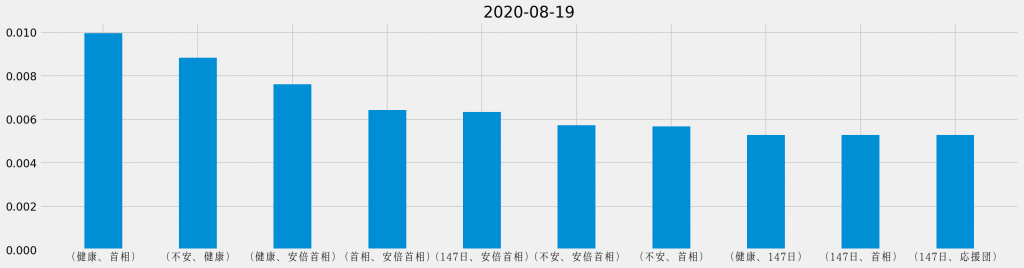
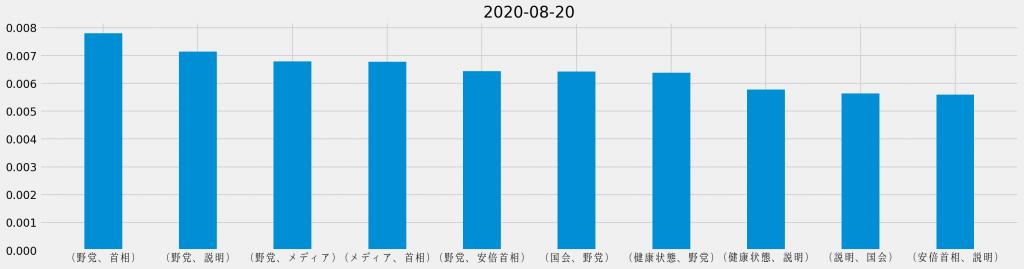
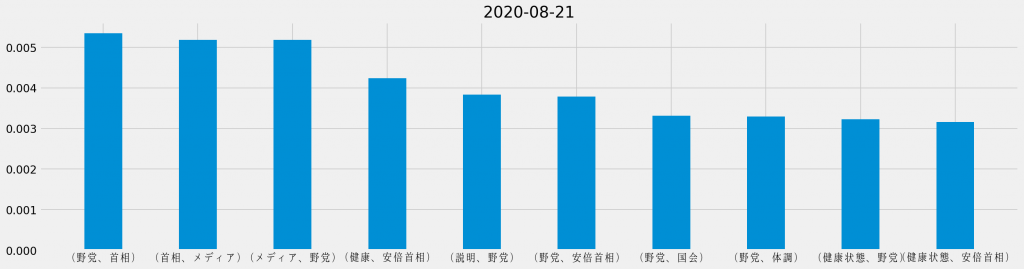
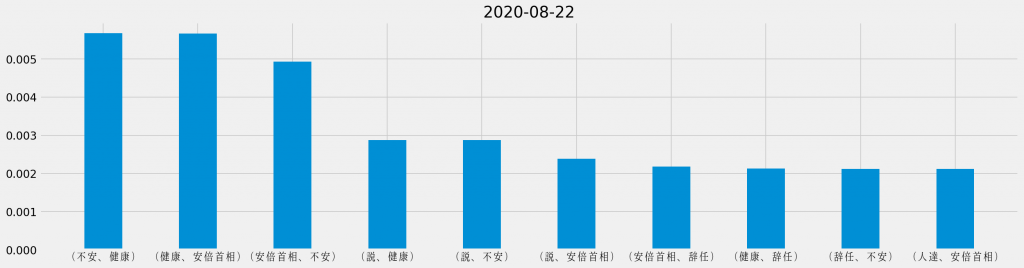
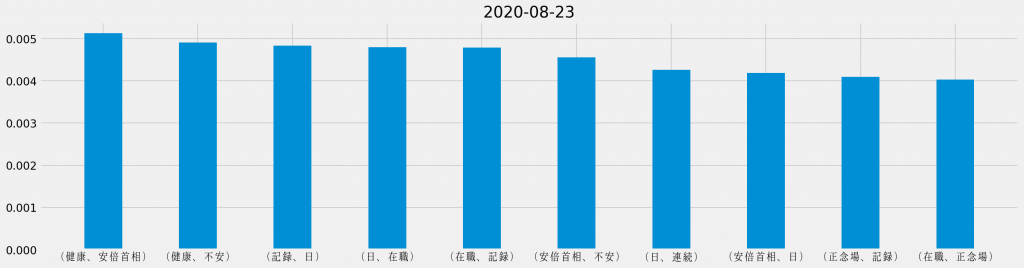
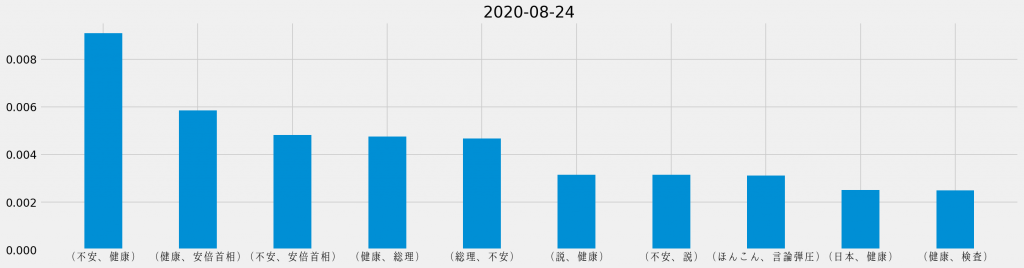
基本的に「安倍首相 健康」のキーワード検索でヒットしたTwitterのツイートを対象としているため、「安倍首相」と「健康」が上位に連なるのは道理だ。その一方で、週の中盤からは「野党」が目立つようになり、最終日には唯一「ほんこん」が登場しているというのは、データが表す際立った特徴と言える。
日ごとの共起ネットワーク
日ごとのデータを対象に、共起確率を重みとした上で、networkxのspring_layoutでネットワーク図を作成してみよう。この関数で利用されているFruchterman-Reingold force-directed algorithmでは、グラフのノードとエッジに仮想的な「力」を割り当る。この時、ノードを結ぶエッジは、ばね(Spring)のように作用する。この作用から力学的エネルギーの低い安定状態を探索することにより、各ノードの位置関係を規定する(Fruchterman, T. M., & Reingold, E. M., 1991)。
可視化した結果がどのような「分布」になるのかは、入力するデータとパラメタによってある程度予期することができる。共起確率を重みとして計算して入力すれば、相対的に共起頻度の低く、相対的にリンクするノードの少ないノードほど、「ばね」の「力」で外部に押し出される。逆に、相対的に共起頻度が高く、相対的にリンクするノードが多いノードほど、ノード集合の中心部分に位置付けられるようになると期待できる。勿論、母集団の特徴次第では、複数のサブ集合に分化する可能性も否定できない。
可視化の対象は、名詞-名詞の組み合わせの場合、共起頻度の高い単語の組み合わせの上位50程度とし、名詞-形容詞の組み合わせの場合は上位100件程度としている。ただし、リンクするノードが著しく少ないノードや後述するストップワードは除外されている場合がある。あるいは共起のペアがそもそも100件以上存在しない場合もある。データの可視化の目的は発見探索にあるのであって、演繹や帰納にあるのではない。そのためここでは厳密解に固執する設定は採らないことにしている。
日ごとの共起ネットワーク図(2020年8月17日、名詞-名詞)
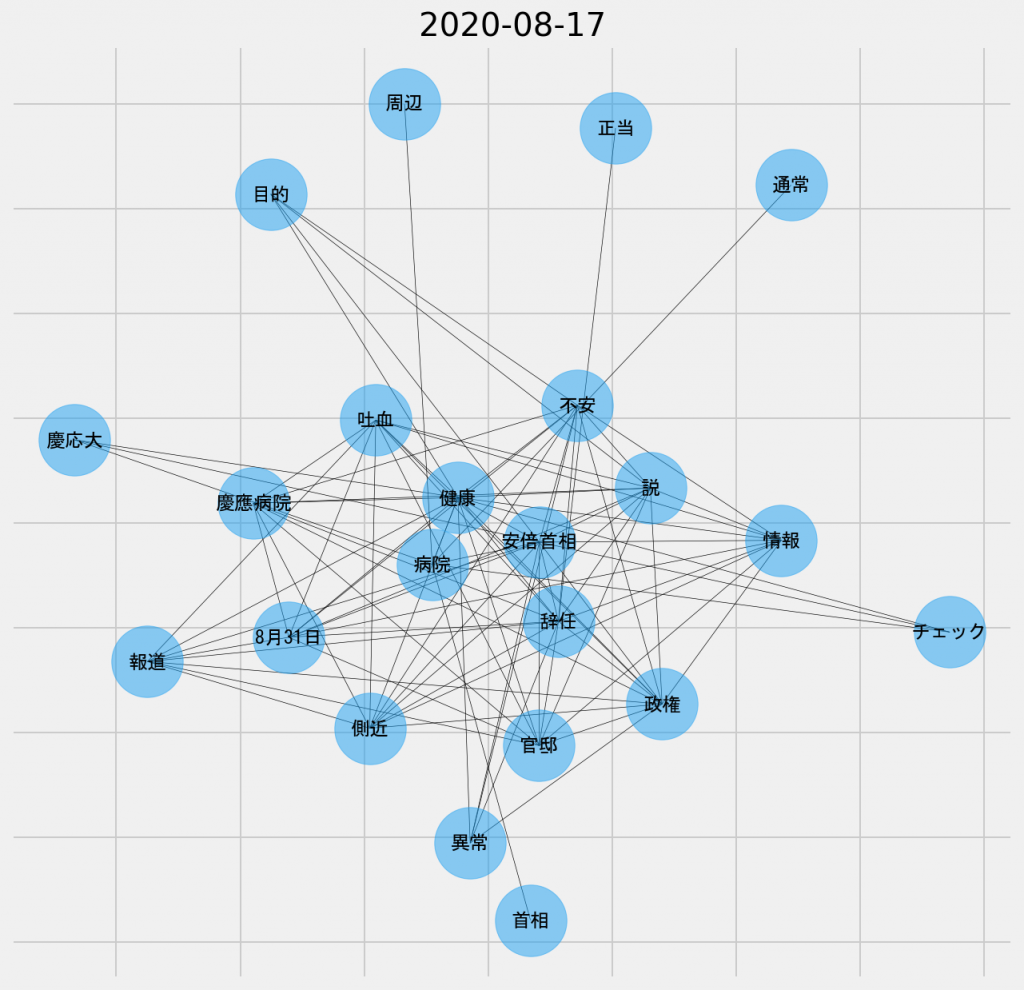
実は8月17日の時点で、既に「辞任」というキーワードが頻出していたようだ。
日ごとの共起ネットワーク図(2020年8月17日、名詞-形容詞)
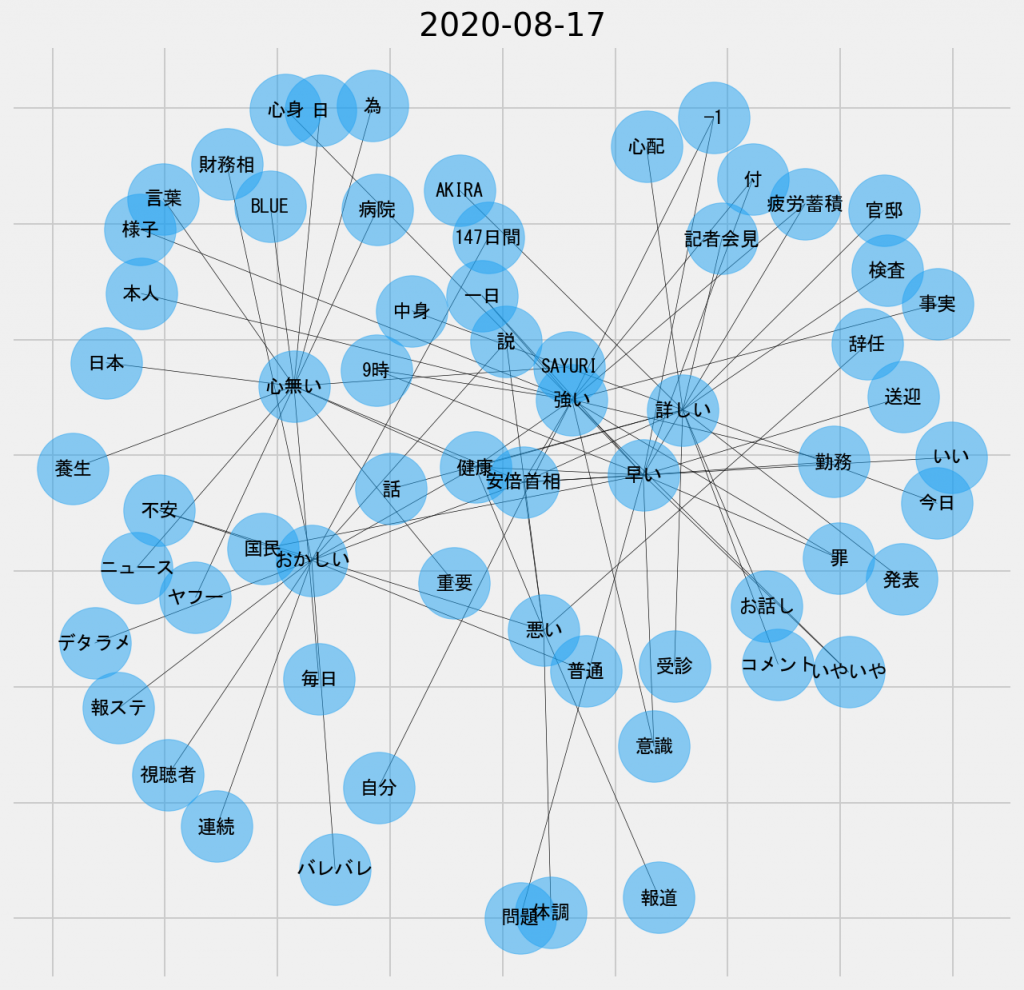
名詞と形容詞の共起を探ってみると、どうも「心無い」や「おかしい」というノードが頻出しているようだった。これは、安倍首相の健康問題に対する評判が、当時は「心無い」コメントや「おかしい」コメントから始まったということを意味するのだろうか。あるいは、「心無い」コメントに対して、「それはおかしい」という反対意見が生じていたのだろうか。
日ごとの共起ネットワーク図(2020年8月18日、名詞-名詞)
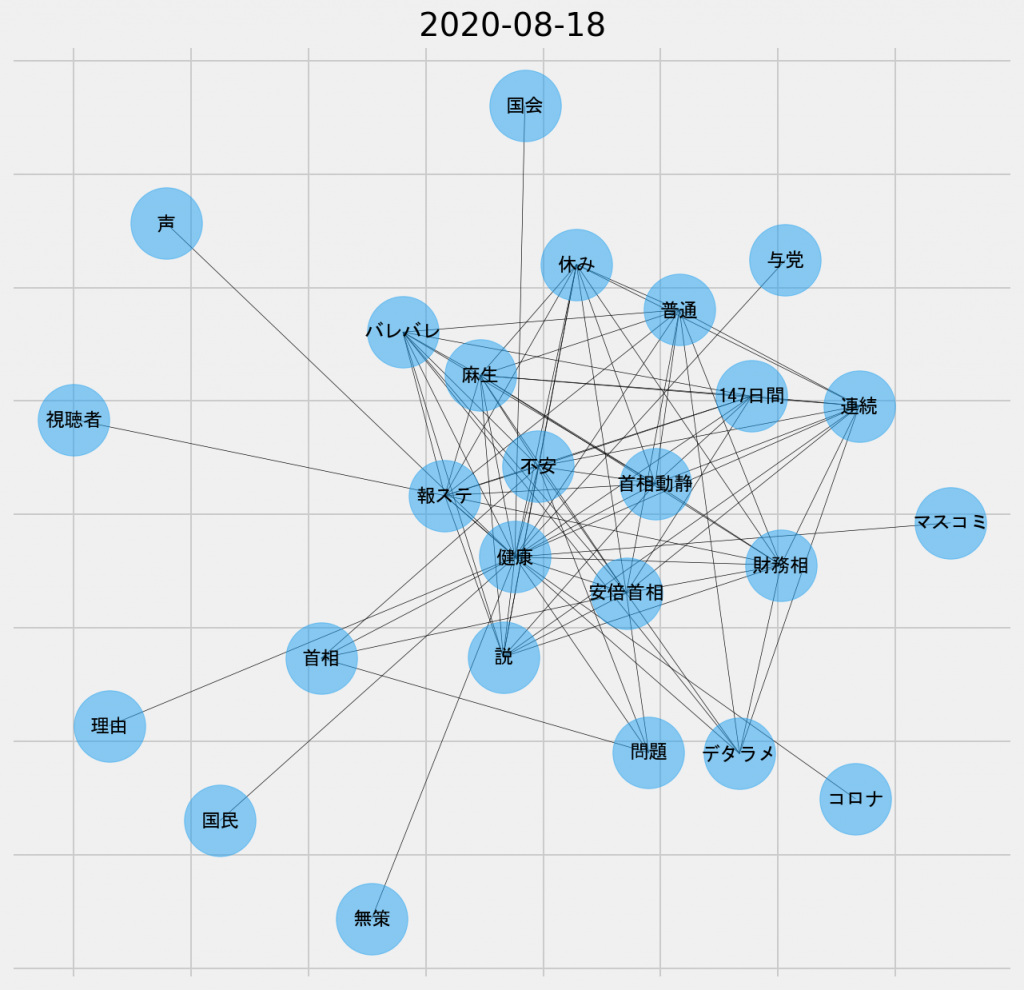
「財務相」や「麻生」のキーワードが頻出している。麻生大臣の安倍首相の健康問題についてのコメントが主題になったのか、あるいは麻生暫定内閣がこの時点で予期されていたのかもしれない。
日ごとの共起ネットワーク図(2020年8月18日、名詞-形容詞)
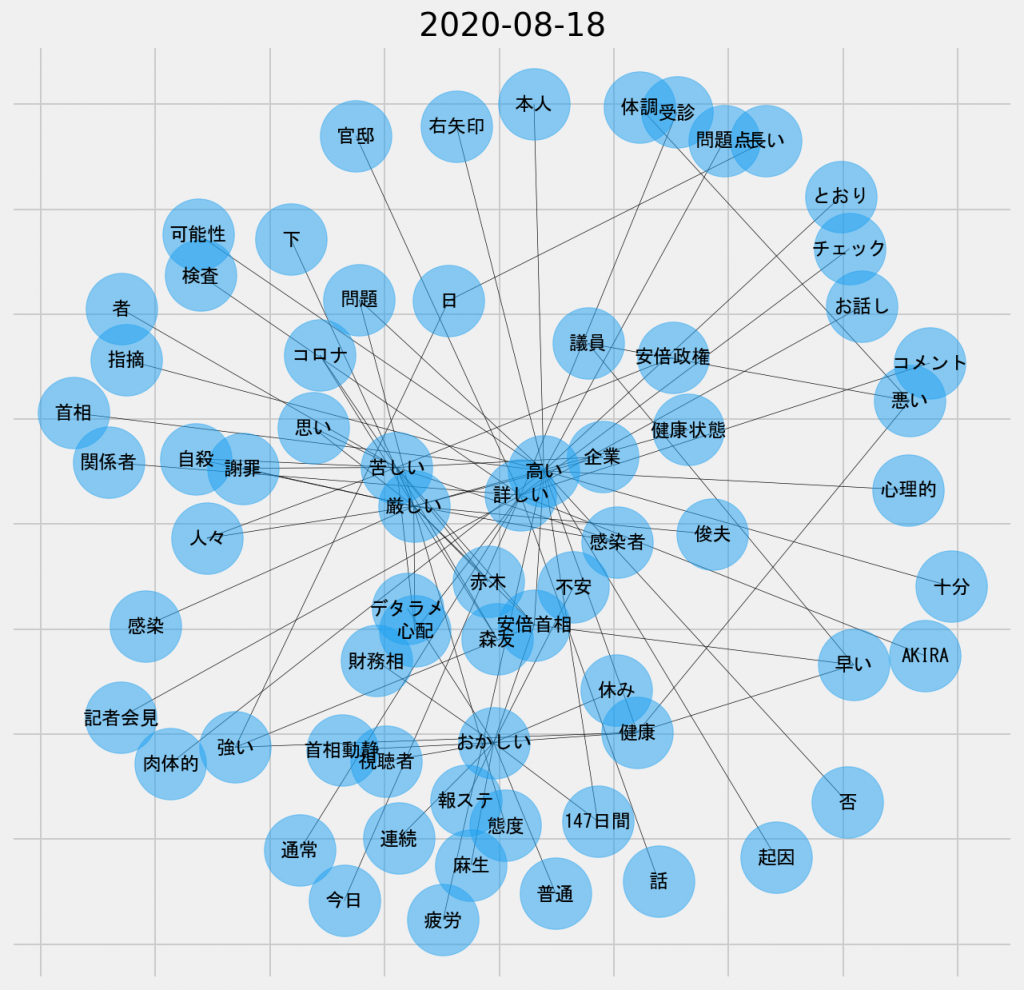
「苦しい」や「厳しい」というキーワードが頻出していた。これらは健康問題を主題として参照しているので、体調を表現した言葉なのかもしれない。
一方、「おかしい」というノードはこの日も登場している。
日ごとの共起ネットワーク図(2020年8月19日、名詞-名詞)
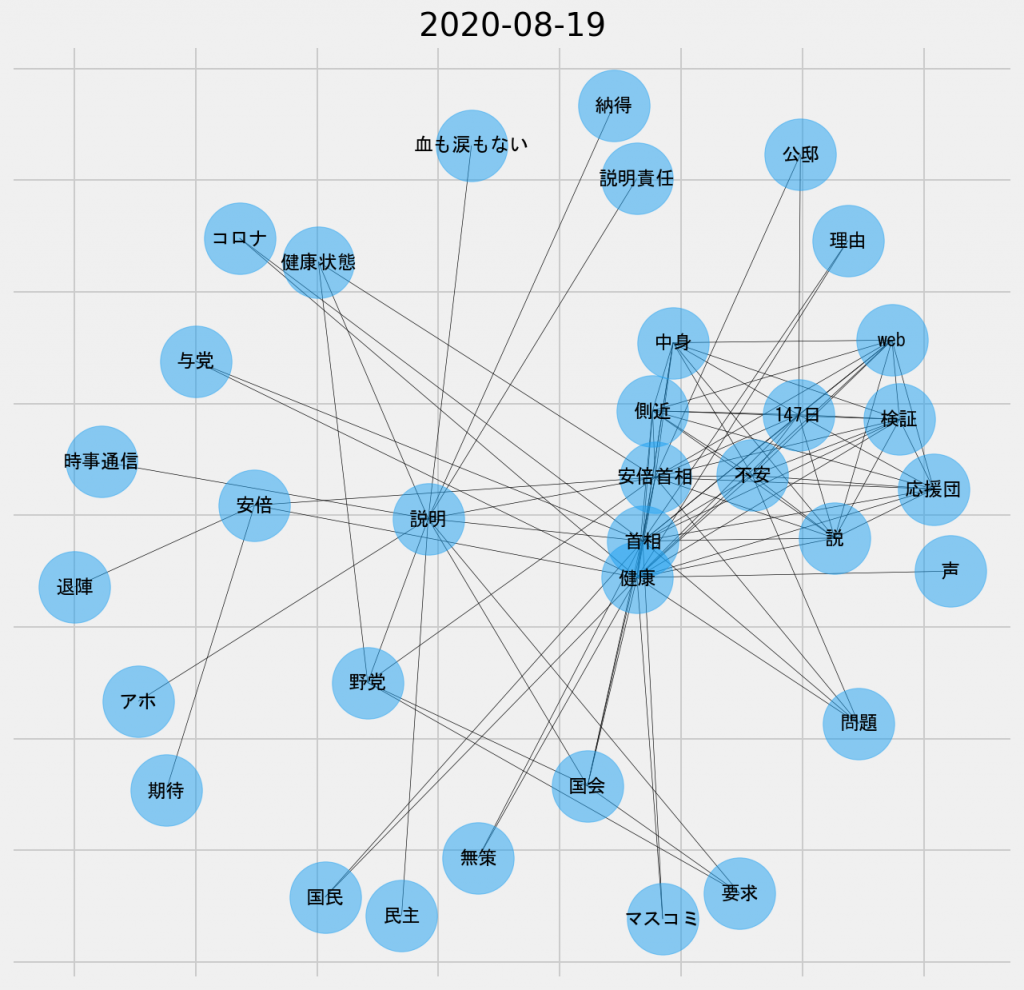
「国会」や「説明」や「民主」というキーワードから、一部の政党の者たちが、安倍首相の健康問題に関する国会での説明を求めた件が反映されている。周辺を見渡してみると、「安倍」と「退陣」がリンクしている一方で、「安倍首相」と「応援団」がリンクしてもいる。
日ごとの共起ネットワーク図(2020年8月19日、名詞-形容詞)
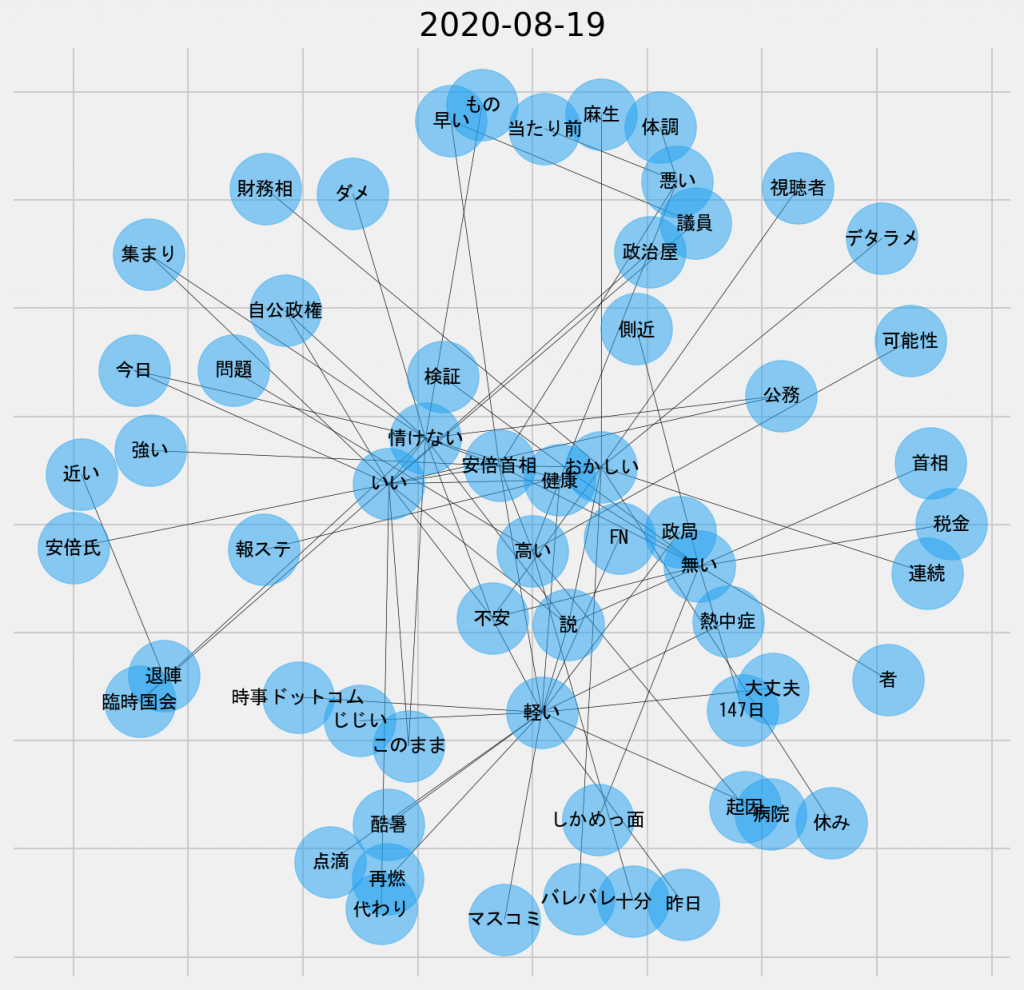
この日もまた「おかしい」というノードが頻出しているが、それよりも「軽い」や「情けない」という用語が目立つようになっている。
日ごとの共起ネットワーク図(2020年8月20日、名詞-名詞)
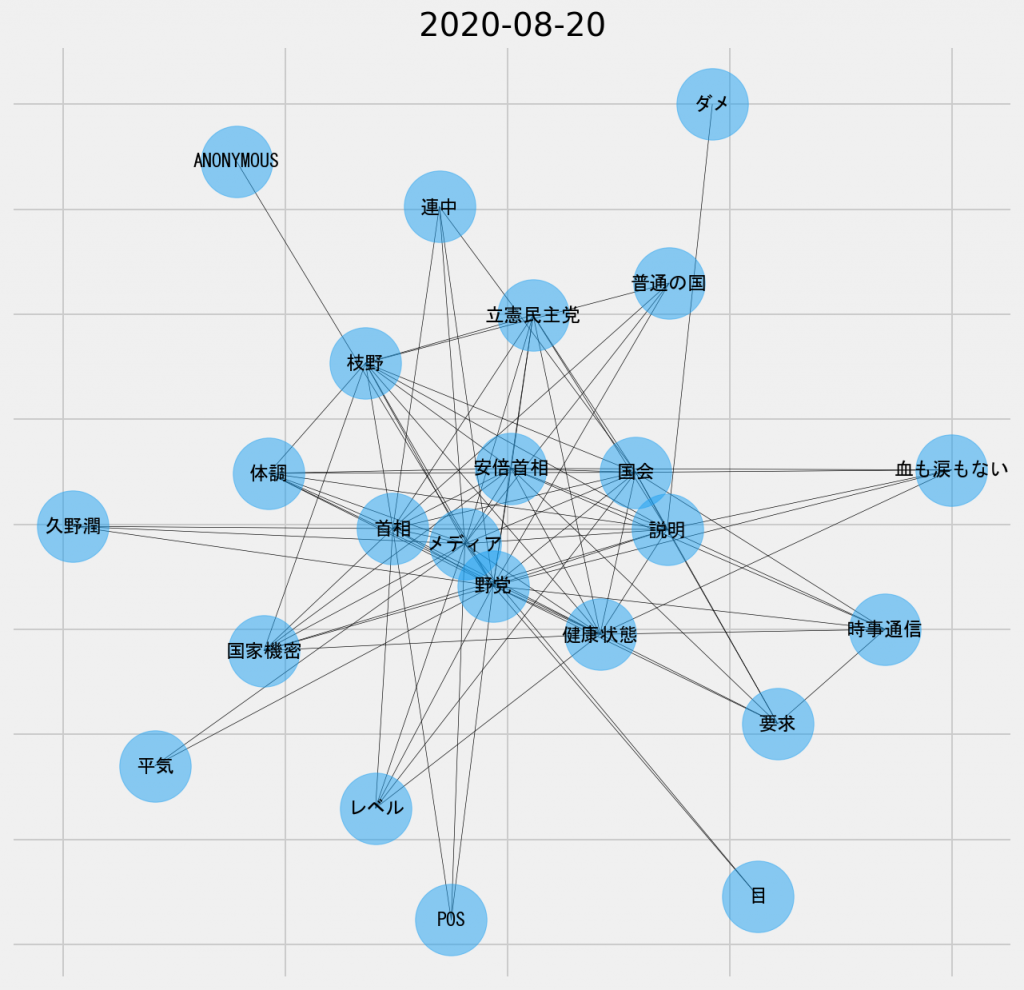
「立憲民主党」、「枝野」、「野党」というキーワードが中心部分で多くのノードとリンクしている。上述した「国会」での「説明」の件の派生と考えられる。また、時を同じくして、「メディア」というキーワードもまた中央部分に食い込んできている。
日ごとの共起ネットワーク図(2020年8月20日、名詞-形容詞)
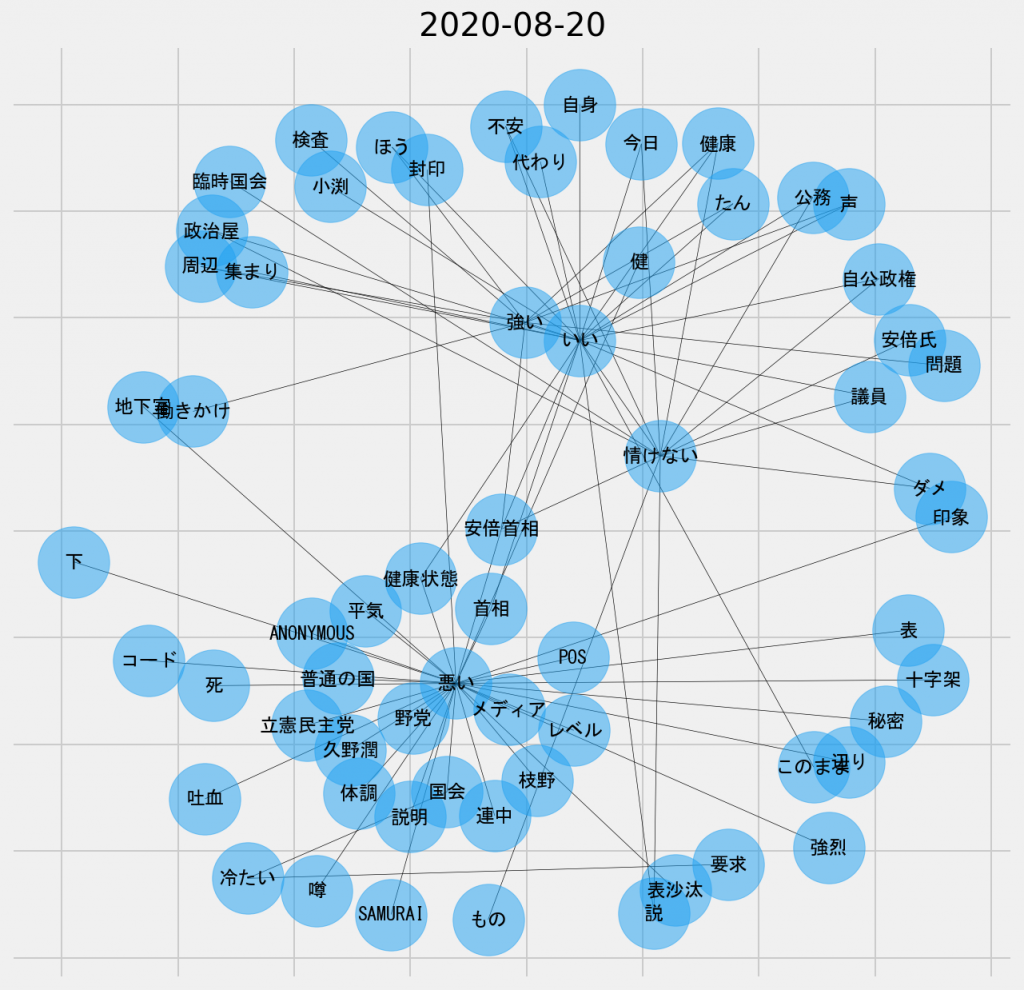
この日は「情けない」と共に「悪い」というノードがサブ集合の中央部分に君臨している。実は「悪い」のノードは、8月19日までのネットワーク図にも表れていた。ここにきてこのノードが多くのノードと結び付くようになったということは、徐々に主題が「誰が悪いのか」や「何が悪いのか」に移り変わっていると推論できる。
日ごとの共起ネットワーク図(2020年8月21日、名詞-名詞)
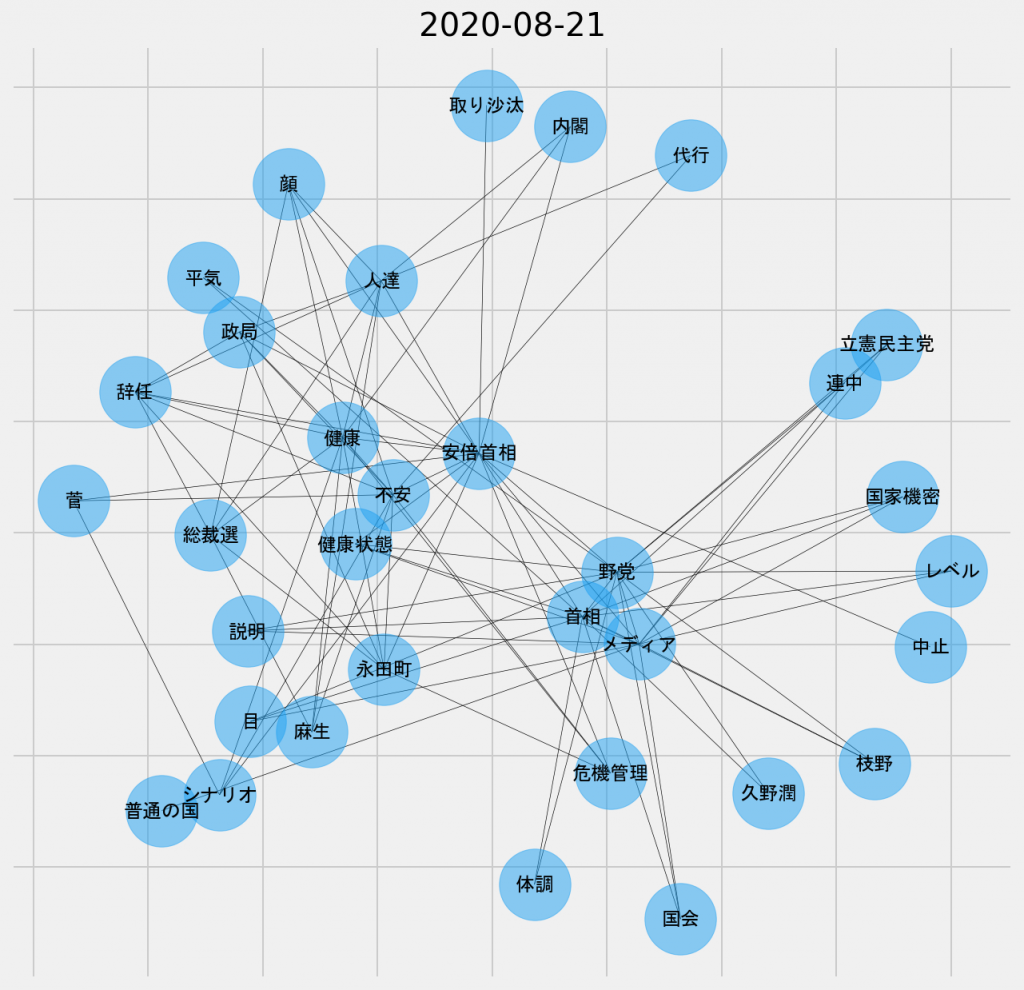
「健康」、「不安」、「健康状態」といったノードを中心とするサブ集合と、「野党」、「メディア」、「首相」といったノードを中心とするサブ集合に、大別することができる。「国家機密」とリンクしていることからもわかるように、「首相」の「健康状態」という一国の「国家機密」を「国会」で「説明」させようとする「野党」や「メディア」そのものが、「安倍首相の健康問題」から派生して、新たな議論の主題になったのだと考えられる。
日ごとの共起ネットワーク図(2020年8月21日、名詞-形容詞)
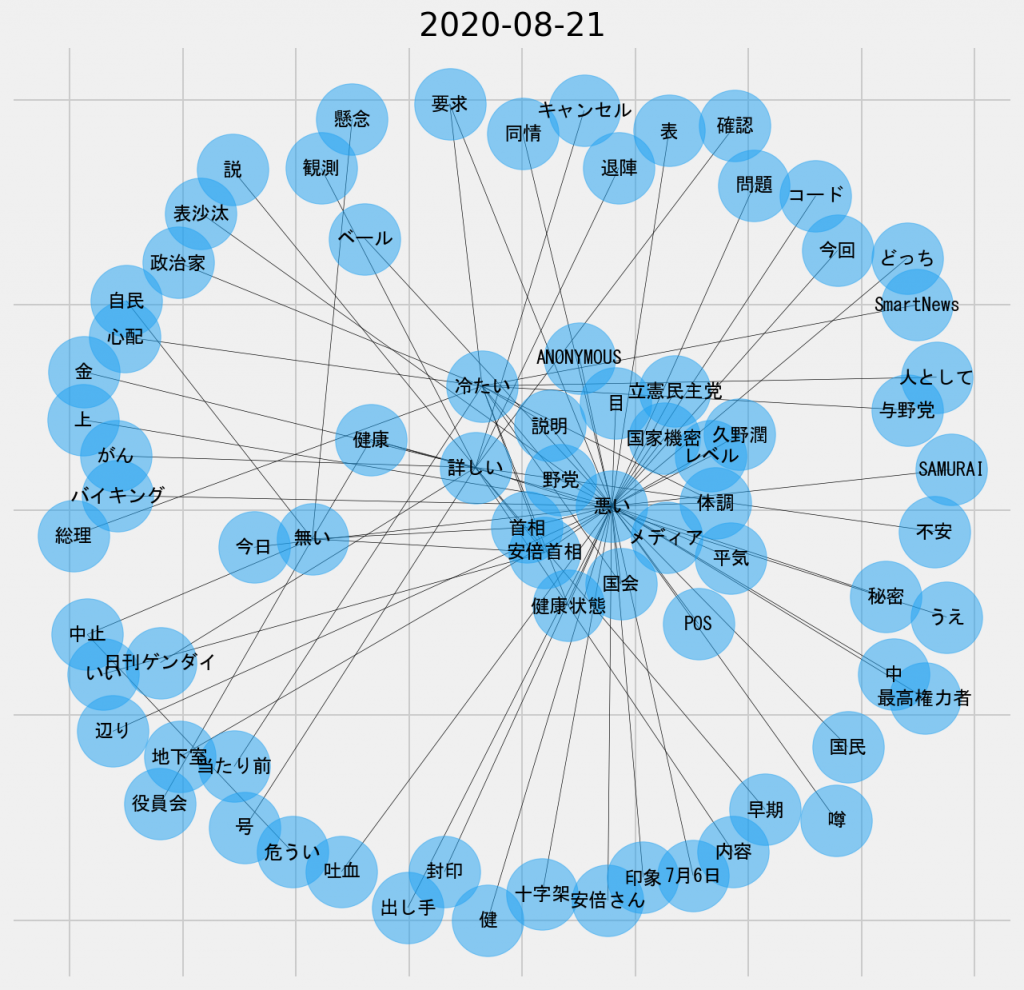
この日になると、本格的に「悪い」のノードが全体の中央部分に肉薄するようになった。「誰が悪いのか」や「何が悪いのか」を主題とする議論が本格的に活性化したということだろうか。名詞-名詞のネットワーク図を前提とするなら、ここでいう「誰が」や「何が」に該当する候補となるのは、「野党」、「メディア」、「首相」のいずれかなのだろうか。
日ごとの共起ネットワーク図(2020年8月22日、名詞-名詞)
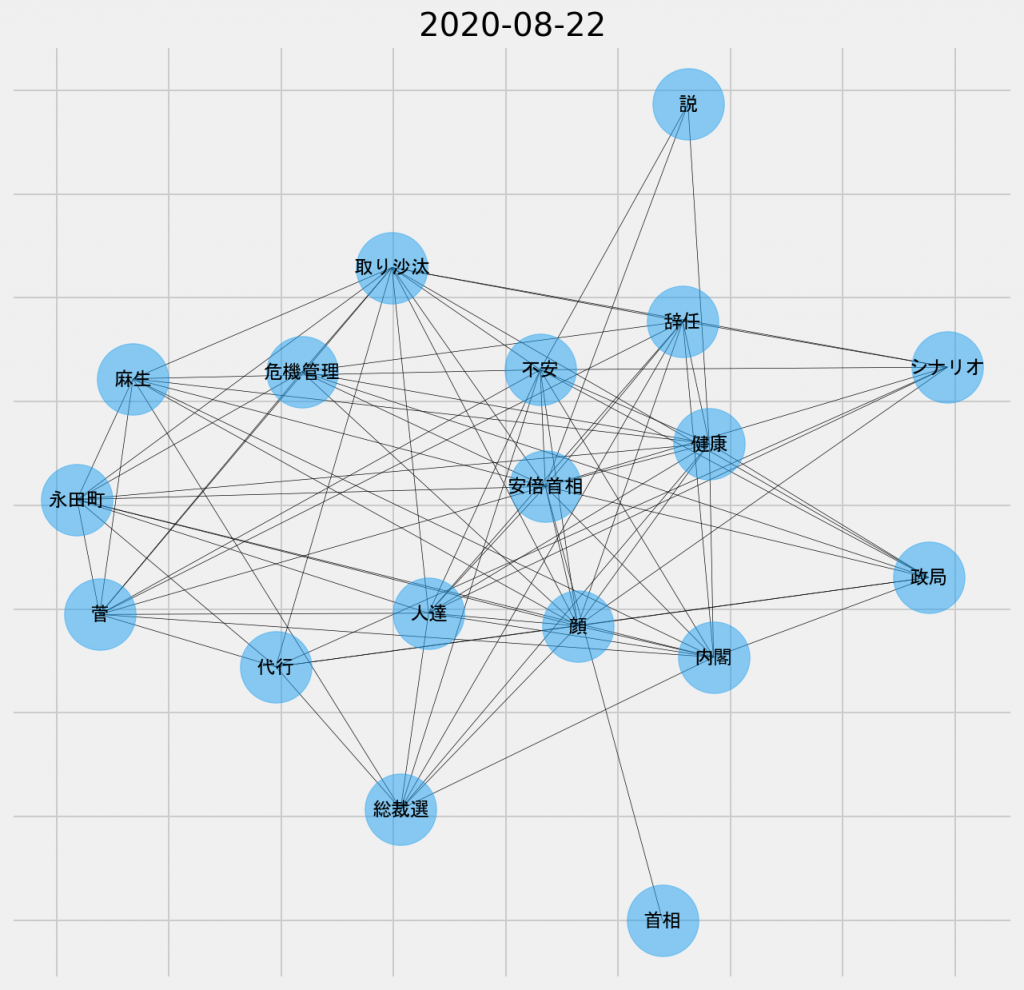
「総裁選」、「麻生」、「菅」のキーワードからもわかるように、この日は「ポスト安倍」の可能性が議論の主題となっていたようだ。
日ごとの共起ネットワーク図(2020年8月22日、名詞-形容詞)
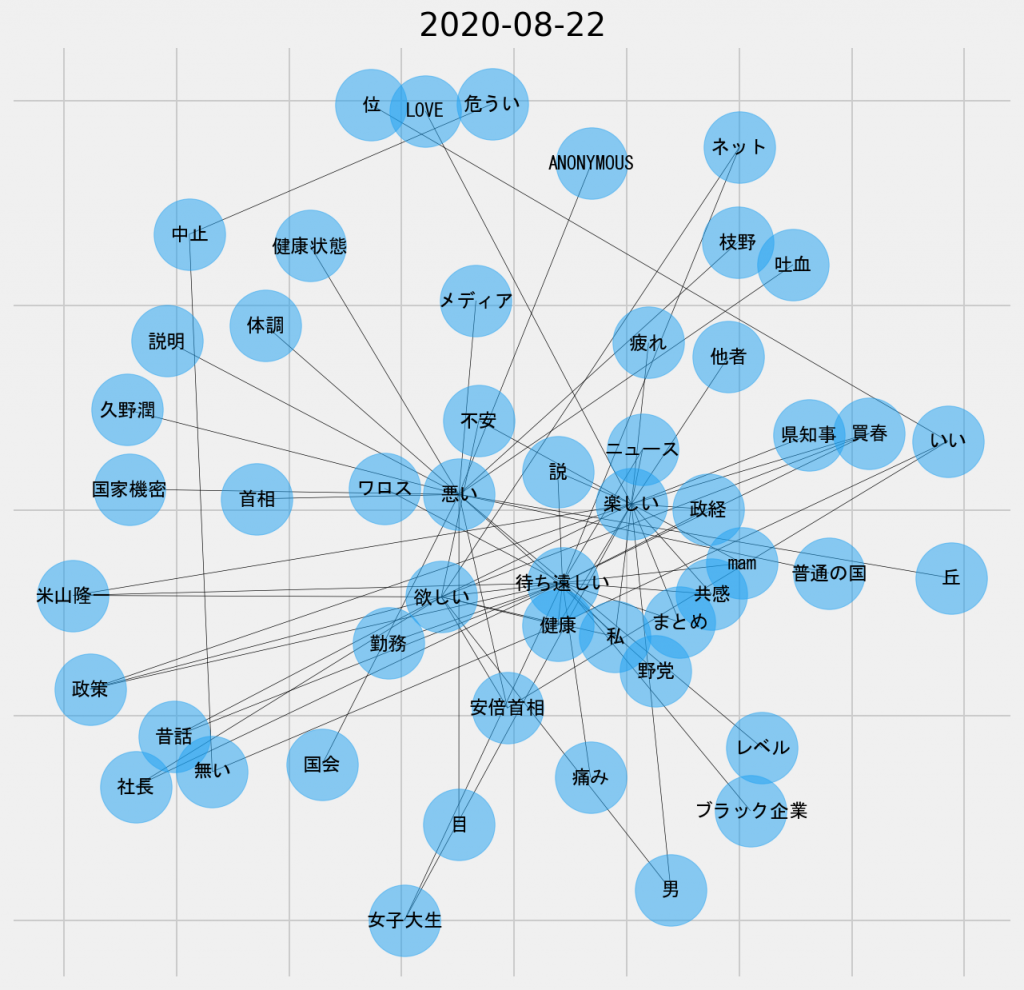
「悪い」は相変わらず中央に位置しているが、一方で「楽しい」、「欲しい」、「待ち遠しい」といったやや肯定的な表現のノードが多くのリンクを結んでいる。上述したように、「総裁選」が主題となったことで、「ポスト安倍」に対する期待が生じたのだろうか。
日ごとの共起ネットワーク図(2020年8月23日、名詞-名詞)
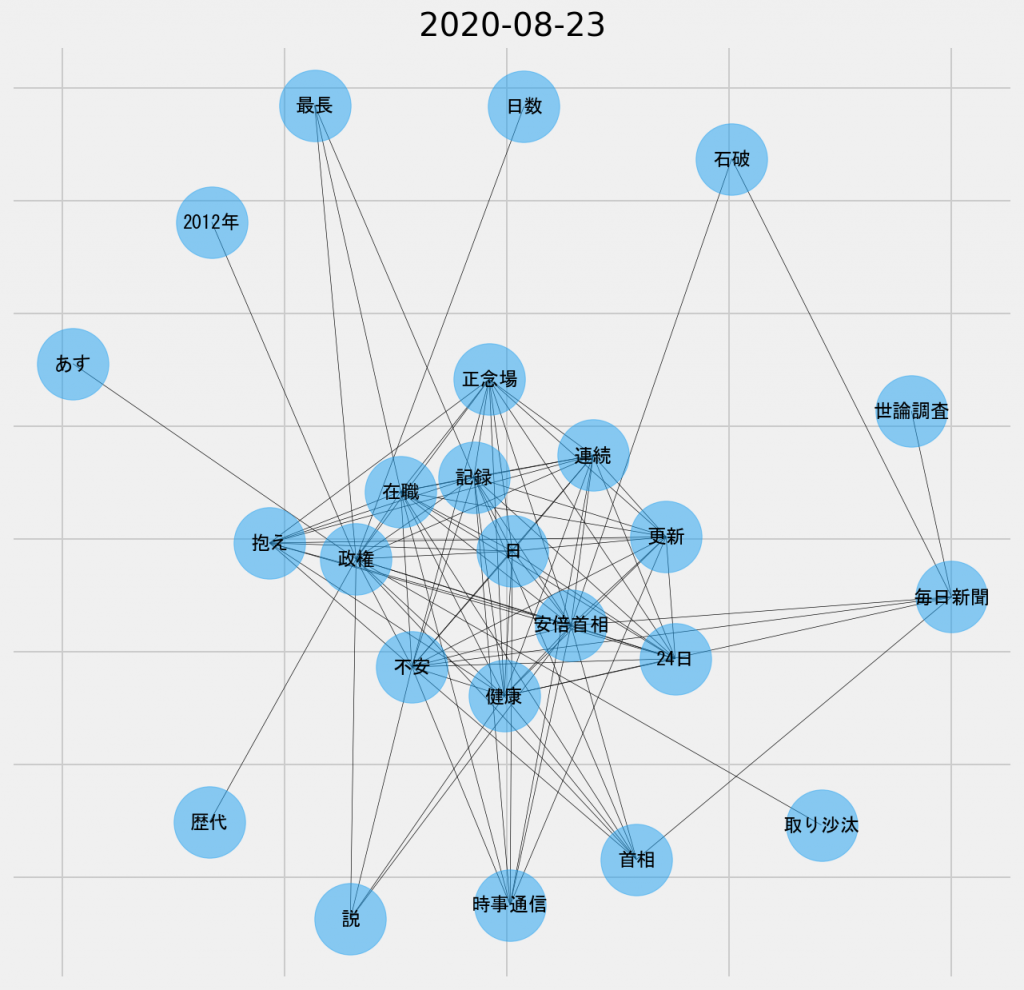
この日は、「麻生」や「菅」の代わりに、「毎日新聞」と「世論調査」と「石破」といったキーワードが新たに登場している。しかしこれらのノードは、中央部分とのリンクが少ない。脇役的な主題なのだろう。
それよりも、「在職」と「記録」のノードと共に、「正念場」や「不安」といったノードが中央に位置付けられているのは、やはり安倍首相の健康問題そのものがより重要な主題であることを想起させる。
日ごとの共起ネットワーク図(2020年8月23日、名詞-形容詞)
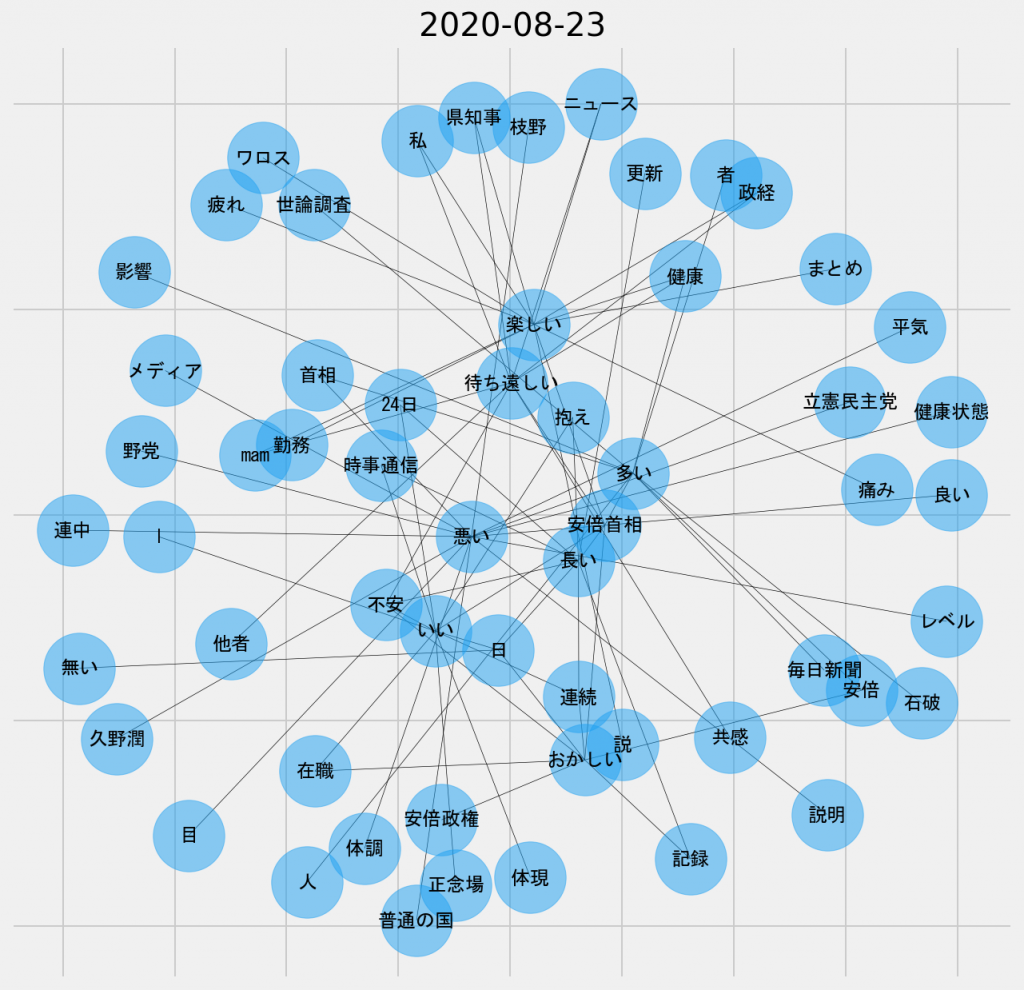
「悪い」、「楽しい」、「待ち遠しい」という否定的なノードと肯定的なノードが中央部分で混在している。それぞれのポジションから、それぞれの理念が語られ、それぞれの意見が衝突しているのかもしれない。
日ごとの共起ネットワーク図(2020年8月24日、名詞-名詞)
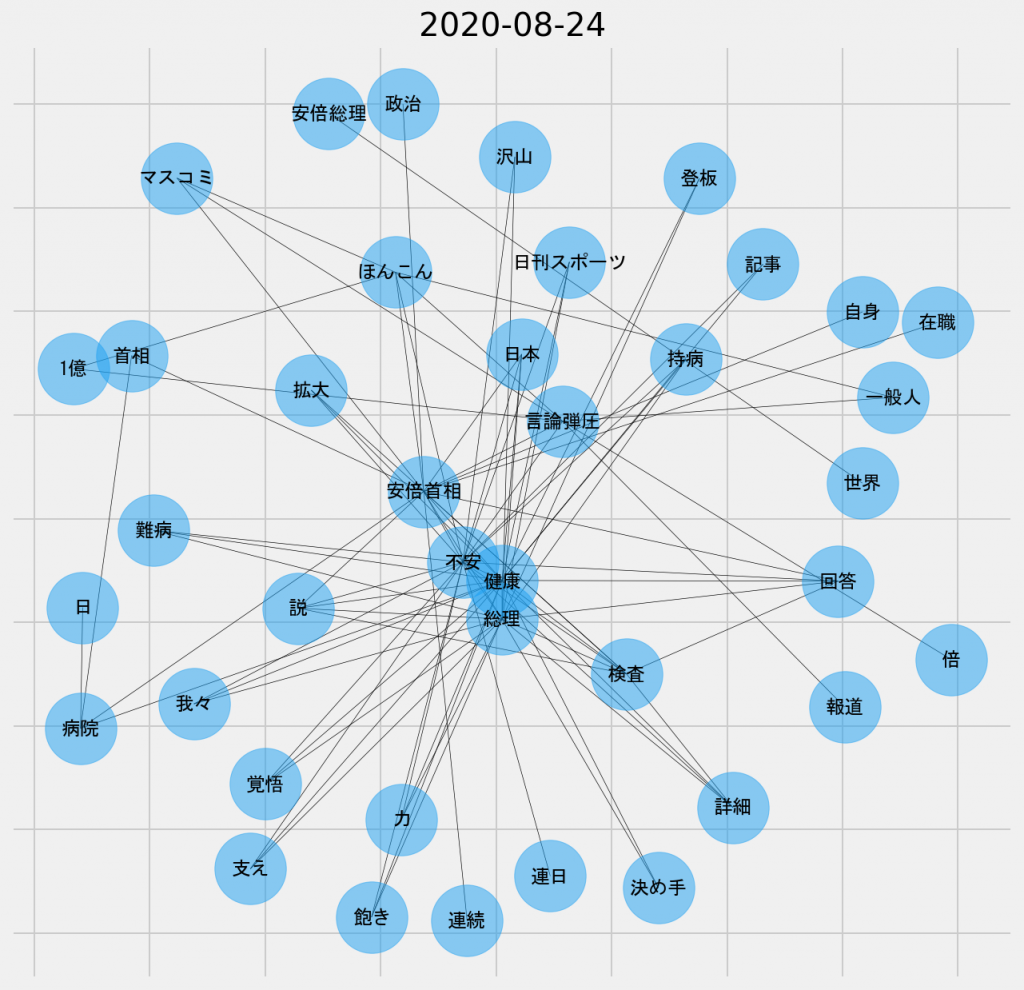
先ほどの棒グラフでもこの日だけ登場した「ほんこん」のノードは、「言論弾圧」のみならず、「マスコミ」や「一般人」ともリンクしていることがわかる。マスコミに映されたタレントのほんこん氏の発言が、物議を醸したのだろう。
日ごとの共起ネットワーク図(2020年8月24日、名詞-形容詞)
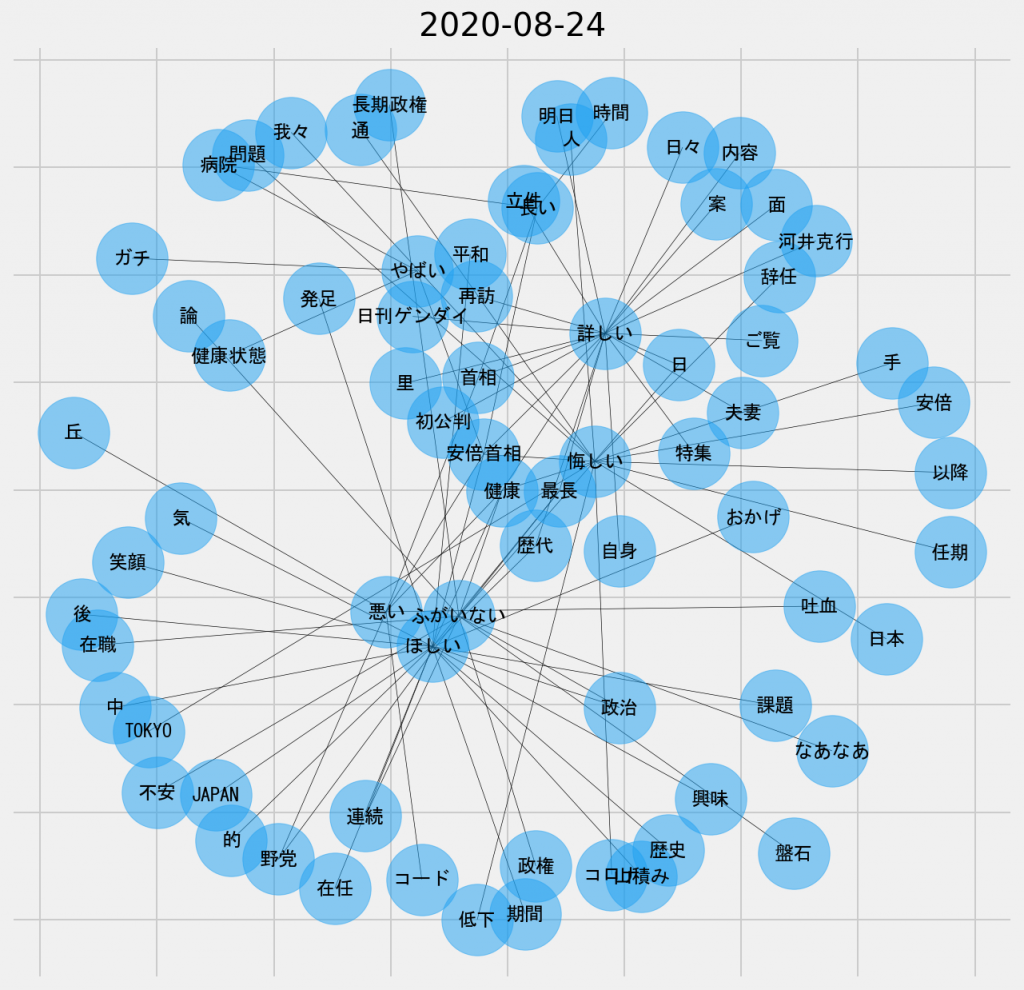
ここにきて、「悪い」のほか、「ふがいない」や「悔しい」といった否定的な表現のノードが散見されるようになった。ほんこん氏の発言が物議を醸した件とも関連するのかもしれないが、どちらかと言えば、首相が再度通院したことに起因しているようにも思える。
7日間の共起ネットワーク
この7日間の共起ネットワーク図を作画すると、次のようになった。
7日間の共起ネットワーク図(名詞-名詞)
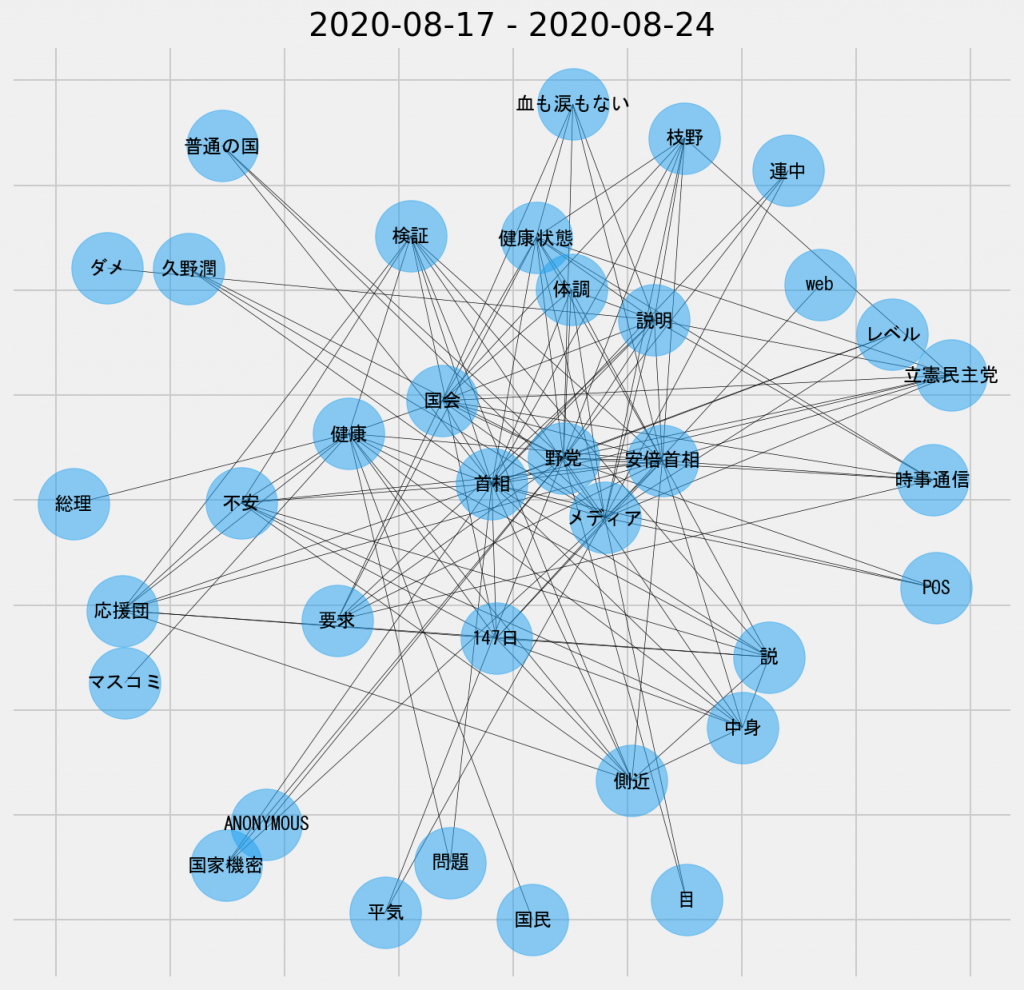
概ね、これまでの主題の概要となっている。
7日間の共起ネットワーク図(名詞-形容詞)
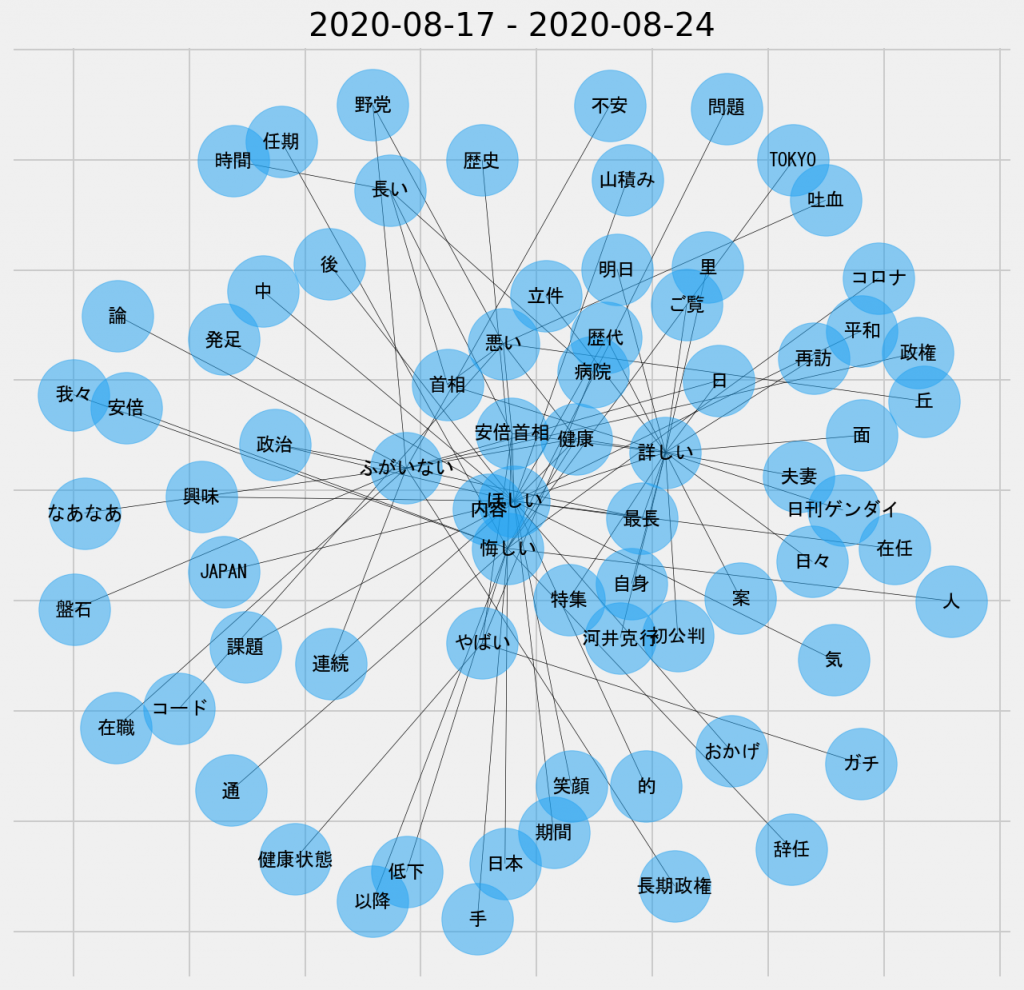
こちらもやはり、「悪い」などのノードが中心に位置しているため、これまでの概要を表現していると言える。
派生問題:何を可視化し、何を不可視に留めておくのか
以上の可視化の結果を観るに、安倍首相の健康問題に起因した多くのツイートは、様々な二項対立図式を構成していたことがわかる。例えば、以下のような図式は顕著に発見された。
- 安倍首相の「健康状態への楽観的な展望」と「健康悪化を不安視する展望」の対立
- 「147日」の間休まずに働いた安倍首相に対する「肯定的な評価」と「否定的な評価」の対立
- 安倍首相の在職記録に対する「肯定的な評価」と「否定的な評価」の対立
- 安倍首相の「続投への期待」と「辞任への期待」の対立
- 「誰が悪いのか(あるいは悪くないのか)」についての対立
- 「何が悪いのか(あるいは悪くないのか)」についての対立
特に安倍首相の健康状態に対する楽観論と悲観論の対立と、「続投への期待」と「辞任への期待」の対立は、今後の日本社会の構造がどのように変動するのかについての不確実性を反映していたと考えられる。こうした二項対立図式は、Twitterの「感情分析」の常套手段となっている極性分析の問題として導入し易い。何か特定の主題を設定して初めて、それに対する「肯定的」、「中立的」、「否定的」の分類が可能になるためだ。
一連のデータの可視化によって、我々は安倍首相の健康状態を巡るTwitterを対象とした「感情分析」の出発点に立つことができた。この路線で「感情分析」を実施すれば、今後の日本社会の構造がどのように変動するのかを背景とした「理念」の推論にも役立てるであろう。
ところで、こうしたデータの可視化は、しばしば「感情分析」のような機械学習の問題解決に着手する前段階に実施される「特徴工学(Feature Engineering)」として認識されているが、機械学習の本題としては認識される傾向が弱いように思われる。
一般的にデータ分析は、データの可視化に始まり、データの可視化に終わる。これはTwitterの「感情分析」にも該当する。だがこのデータの可視化は、「可視」と「不可視」の区別を前提とする。データの可視化とは、ある特定のデータを可視化すると共に、その他のデータを不可視に留めておくことを意味する。そのため、データを可視化する際には、有用性や効率性や合理性の観点から、何を不可視に留めておいた方が良いのかを決定しなければならない。
例えば、上述した「誰が悪いのか(あるいは悪くないのか)」についての対立は、しばしば個人への道徳的な攻撃に発展し易い。多くの道徳的なコミュニケーションは、善と悪の区別や尊敬と軽蔑の区別などのような形式によって成り立つ。だがこうしたコミュニケーションは、しばしば「そういうお前はどうなんだ?」という反問によって、収拾のつかない口喧嘩へと発展していく。
これは、善と悪の区別や尊敬と軽蔑の区別によって成り立つコミュニケーションが、何らかの個別具体的な結論へと収束していく訳ではないということを意味する。「誰が悪いのか(あるいは悪くないのか)」についての対立は、誹謗中傷や罵詈雑言のワードを用いた言い争いとなる。(こうしたワードは、少し厳しめに「ストップワードリスト」を設定すれば、跡形も無く消え去るだろう)。
こうした可能性を考慮するなら、道徳的な攻撃のための自然文については、予めフィルタリングしておくのも一手かもしれない。「文書自動要約器(Automatic Document Summarizer)」の中には、以下の記事のように、テキストフィルタリングを実行することによって、主題やトピックの抽出を実現しているアルゴリズムもある。
この類のアルゴリズムを利用すれば、重要ではないと推論できるツイートを予めフィルタリングした上で、カルチュロミクス的な集計を実施するという手続きも想定できる。こうした手法については、また別の機会に検討することにしたい。
参考文献
- Aiden, E., & Michel, J. B. (2013). Uncharted: Big data as a lens on human culture. Penguin.
- Fruchterman, T. M., & Reingold, E. M. (1991). Graph drawing by force‐directed placement. Software: Practice and experience, 21(11), 1129-1164.
- Jianqiang, Z., Xiaolin, G., & Xuejun, Z. (2018). Deep convolution neural networks for twitter sentiment analysis. IEEE Access, 6, 23253-23260.
- Kouloumpis, E., Wilson, T., & Moore, J. (2011, July). Twitter sentiment analysis: The good the bad and the omg!. In Fifth International AAAI conference on weblogs and social media.
- Severyn, A., & Moschitti, A. (2015, August). Twitter sentiment analysis with deep convolutional neural networks. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval (pp. 959-962).